Opacità e Trasparenza Algoritmica: è possibile o auspicabile fare luce sulle black box?
di Fabio Gnassi
A differenza delle grandi invenzioni del passato, che erano tangibili e visibili, gli algoritmi operano in modo opaco, nascosti dietro un complesso linguaggio matematico. In un momento storico in cui queste entità digitali non solo osservano, ma influenzano le nostre vite quotidiane la necessità di fare luce su questi meccanismi è diventata una necessità.
Claudio Agosti (vecna) nasce come hacker autodidatta nel secolo scorso, e la parte della sfida che lo affascina è come l’umanità può utilizzare la rete come strumento di liberazione e disintermediazione. Per questo, crittografia, peer to peer, aggiramento della censura e critica al potere nel digitale sono il suo pane quotidiano. Socio di “Hermes – Hacking for Human Rights”.
Fondatore di Tracking Exposed, un progetto nato nel 2016 come pioniere nell’analisi degli algoritmi, ha successivamente diversificato le sue attività nel 2023 dando vita a tre nuovi progetti: Makhno, AI Forensics (di cui è co-fondatore) e Reversing.Work. Quest’ultimo, dedicato al Reverse Engineering — un processo di analisi che consente di ricostruire il funzionamento interno di un sistema — ha svolto un ruolo chiave nell’avvio di un’indagine contro Foodinho, la società di food delivery tramite cui Glovo opera in Italia. L’indagine si è conclusa con l’imposizione di una sanzione di 5 milioni di euro da parte del Garante per la protezione dei dati personali italiano.

Il suo interesse per gli algoritmi e il loro funzionamento è alla base di Reversing.Works e AI Forensic. Potrebbe descrivere questi due progetti, evidenziando le implicazioni che ne hanno determinato la nascita e gli obiettivi che si prefiggono di raggiungere?
Sono 20 anni che ho scritto il primo articolo di critica verso il motore di ricerca Google, in cui identificavo il potere dell’azienda americana di plasmare la percezione pubblica attraverso lo studio e la manipolazione dei profili conoscitivi dei suoi utenti. All’epoca tutto questo era difficile da provare, sembrava una teoria del complotto. Ma i tempi per capire il potere che gli algoritmi hanno nell’influenzare la società erano già maturi. Basti pensare che lo studio in cui si evidenzia la capacità di Facebook di giocare con le emozioni dei suoi utenti, controllando ciò che vedono, è stato pubblicato 10 anni fa. Purtroppo però, affinché questo problema iniziasse a divenire chiaro anche al di fuori della mia bolla sono stati necessari degli abusi, dei whistleblowers.
Alla luce di quanto detto, l’obiettivo primario del mio lavoro è di alzare la consapevolezza. Si deve capire che non si è padroni del proprio tempo e della propria esperienza digitale. Si pensa di essere in controllo, ma non è così. L’obiettivo secondario consiste invece nel dare il potere di scelta che hanno gli algoritmi ai cittadini. L’algoritmo opera come un filtro che seleziona le informazioni per decidere quello che deve essere visto, il nostro interesse è di spostare il controllo di questo filtro dalle aziende alle persone.
l’obiettivo primario del mio lavoro è di alzare la consapevolezza. L’obiettivo secondario consiste invece nel dare il potere di scelta che hanno gli algoritmi ai cittadini.
La sua attività di ricerca mira a utilizzare gli algoritmi come strumento per spiegare le nuove dinamiche di potere che caratterizzano l’epoca contemporanea. Potrebbe fornirci alcuni esempi significativi di questo suo lavoro?
Per rispondere a questa domanda farò riferimento a due eventi relativamente recenti.
Il primo risale a Marzo 2022, quando i tiktoker russi hanno iniziato a mostrare del dissenso verso l’invasione dell’Ucraina. Come risposta, il Cremlino fece una legge che vietava l’utilizzo della parola guerra, imponendo l’utilizzo dell’espressione “operazione militare speciale.” Le piattaforme della Silicon Valley si opposero a questa richiesta, mentre TikTok si comportò in maniera diversa, in accordo con una modalità operativa a noi già nota. Infatti, la moderazione dei contenuti di TikTok non è impostata globalmente, ma declinata nazione per nazione, e la moderazione (o blocco, o censura) di un determinato contenuto può avvenire in modalità più o meno subdole. Ad esempio, quando si cerca qualcosa di vietato in Italia, il sistema mostra una scritta che spiega come “quello che cerchi è vietato dalle nostre linee guida” oppure che “non c’è alcun risultato”. Tra le opzioni censorie di TikTok c’è anche l’inquinamento (pollution) dei risultati, attraverso la proposizione di una sfilza di video che non c’entrano nulla con l’oggetto della ricerca.
Questa era stata una ricerca svolta con l’Università di Amsterdam, l’immagine sintetizza il risultato:
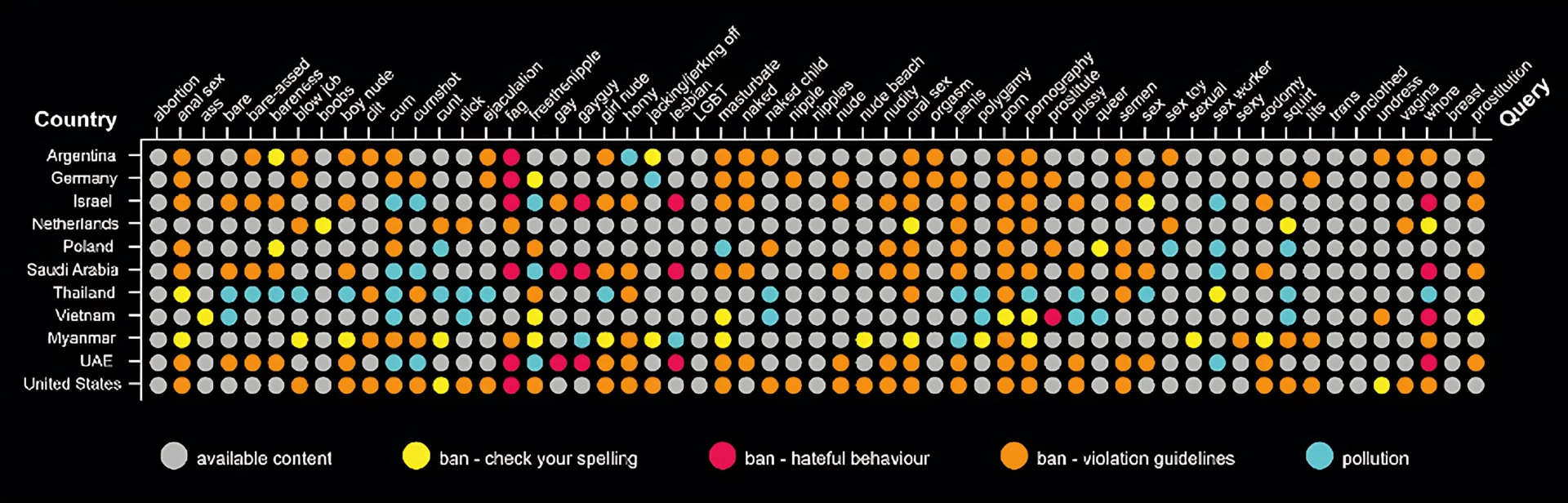
In verticale vedi i “punti di uscita”, ovvero gli stati in cui sono state effettuate le ricerche, infatti grazie all’utilizzo di una VPN è possibile ingannare l’algoritmo di TikTok facendogli credere di trovarsi in diverse parti del mondo. In questo modo abbiamo potuto studiare i risultati ottenuti dalla ricerca di parole chiave (di matrice sessuale) che vedete nella barra orizzontale. Lo scopo della ricerca era quello di verificare se in una particolare nazione una certa parola chiave è bloccata o meno. I risultati ottenuti ci permettono di osservare tre diversi tipi di “ban” e vari tentativi di inquinamento, che nel grafico vengono rappresentati con colori diversi.
Ma torniamo all’invasione dell’Ucraina: sebbene sia facile per TikTok bloccare alcune parole chiave e quindi dimostrare ad uno stato che sta ottemperando con le sue richieste, non è possibile impedire agli utenti di cercare di aggirare i blocchi. Ad esempio, se una influencer pubblicasse un video in cui balla con un cartello con la scritta “stop alla guerra”, senza utilizzare hashtag e senza menzionare la parola “guerra” nella descrizione, per TikTok sarebbe molto difficile rimuoverlo automaticamente. L’intervento avverrebbe solo dopo che il video avesse accumulato migliaia di visualizzazioni, rendendo evidente il tentativo di censura e innescando il cosiddetto “Effetto Barbara Streisand” (cercatelo su wikipedia!). Quello che TikTok decise di fare non aveva precedenti. Frammentò la propria rete in modo geografico impedendo l’upload di video da parte dei cittadini Russi, e rendendo invisibile ogni profilo non russo. Nonostante sul piano economico questa scelta possa sembrare un suicidio, questo meccanismo ha permesso alle operazioni di influenza di diffondere i propri contenuti propagandistici a discapito degli avversari politici interni, ai quali non è stata data la stesssa possibilità. Anche perché, come riportato da Motherboard, alcuni influencer sponsorizzati dal Cremlino, erano ancora in grado di caricare nuovi video sfruttando un “giro atipico”. Attraverso l’utilizzo del cellulare era possibile caricare il video e salvarlo come bozza, per poi pubblicarlo tramite un computer geolocalizzato al di fuori della Russia grazie all’uso di una VPN. Il grafico seguente descrive l’impatto che questa azione ha avuto nei video che parlavano dell’invasione:
Questo esempio ci mostra come non sia facile né veloce spiegare il potere che gli algoritmi esercitano sulla società civile. C’è molto contesto da condividere, che poi va unito alle politiche delle diverse piattaforme. Ci sono gli effetti a lungo termine, che possiamo stimare solo con analisi di dati aggregati, ma che per essere verificati richiederebbero sondaggi individuali. Ci sono anche innumerevoli modifiche nel modo in cui queste tecnologie funzionano, che sono cambiamenti invisibili e rapidi, che magari riguardano solo una piccola percentuale di popolazione.
Per questi motivi, produrre indagini che colleghino l’individuale al collettivo è ancora complesso.
L’opacità che caratterizza il funzionamento dei modelli di intelligenza artificiale ha portato alla nascita di un ambito di ricerca chiamato “Explainable AI” (X-AI), dedicato allo sviluppo di modelli basati su algoritmi trasparenti e comprensibili. Qual è lo stato di questa disciplina e come valuta il grado di efficienza di questi strumenti?
Si sta cercando di arginare l’alta marea a mani nude e con i castelli di sabbia. Il deep learning nasce da una cultura in cui i dati sono di proprietà del più forte, e nessuna spiegazione deve essere data. L’idea che l’algoritmo è così complesso che neppure chi ci lavora può spiegarlo è stata diffusa da più di una decade, una narrazione che gioca a favore delle aziende che vedono in questa segretezza una buona ragione per non dover spiegare il loro potere e le sue diramazioni. Il deep learning, e tutta la ricerca che ne deriva tra cui i large language model, stanno dando risultati rivoluzionari, a discapito però di alcuni dei valori che l’informatica dava per scontati. La riproducibilità, per prima cosa. La certezza di avere lo stesso risultato a parità di input non c’è più. E così manca la possibilità che due persone creino lo stesso modello linguistico. Si è passati da una disciplina in cui ogni bit era al suo posto ed il risultato poteva essere ripercorso, ad una disciplina in cui ci si deve fidare del caso. Capisco che davanti alle azioni sorprendenti di questi anni la critica possa sembrare sterile, ma questo è un cambiamento radicale rispetto al modo in cui l’informatica veniva concepita, ed è quello che dà meno garanzie.
Basti pensare a quanto successo con la ricerca sugli organismi geneticamente modificati. In passato si usava esporre i semi a mutazioni casuali usando agenti radioattivi per poi valutare soltanto a posteriori se le mutazioni ottenute andavano bene oppure no. Ora con CRISP e altri sistemi di editing del genoma, si sa dove si sta intervenendo (non si possono prevedere gli esiti, ma almeno si ha un po’ di controllo). L’intelligenza artificiale sta attraversando lo stesso percorso storico. Il problema è di natura teorica, perché questi ultimi 20 anni di produzione informatica hanno abituato gli utenti/consumatori a non farsi domande. Accettare quello che succede, e al massimo spegnere e riaccendere. L’informatica è nata come disciplina che aiuta a ripensare ai problemi, a scomporli, e a rendere alcune parti risolvibili da un calcolatore. E’ una differenza rispetto ai presupposti culturali e agli obiettivi iniziali che ancora faccio fatica ad accettare. I prodotti che state vedendo ora, basati su un’interazione tra utenti ed AI, sono solo una fase. L’obiettivo degli sviluppi correnti è di rendere l’AI invisibile, integrarla nelle operazioni, e potenzialmente rimuovere ulteriore abilità decisionale alle persone.
L’explainable AI (XAI) è una disciplina che tenta di rendere comprensibile il funzionamento dell’algoritmo a chi lo sta sviluppando. Quest’anno ho lavorato insieme a dei sindacati ed altri istituti per chiederci come adottare l’AI sul posto di lavoro. Una delle soluzioni proposte, ma difficilmente applicabile, era quella di adottare sistemi di XAI. Si è pensato di usare questi sistemi sui lavoratori intermediati, come i ciclofattorini, autisti di Uber, etc., ma dal mio punto di vista non è quella la soluzione. Per il lavoratore finale il “come funziona l’algoritmo” potrebbe anche non avere importanza, quello che conta è comprendere come organizzare il proprio tempo e le proprie risorse, e perché questo sia possibile, l’applicazione che si sta utilizzando deve prevederlo. Il principale problema è il modo in cui vengono utilizzate le applicazioni di AI. Quando non ti viene dato alcun modo per imparare, capire, controllare, ma hai solo un modo per usare lo strumento, allora sei l’ultimo esecutore di un lavoro già deciso. Il problema è politico, più che tecnologico. E questa sensibilità emerge anche quando Google decide per te, quando Facebook ti promette di darti solo materiale rilevante, etc. Che sia un language model o un sistema di antispam, la domanda che ci si deve porre è “dove sta il potere?”