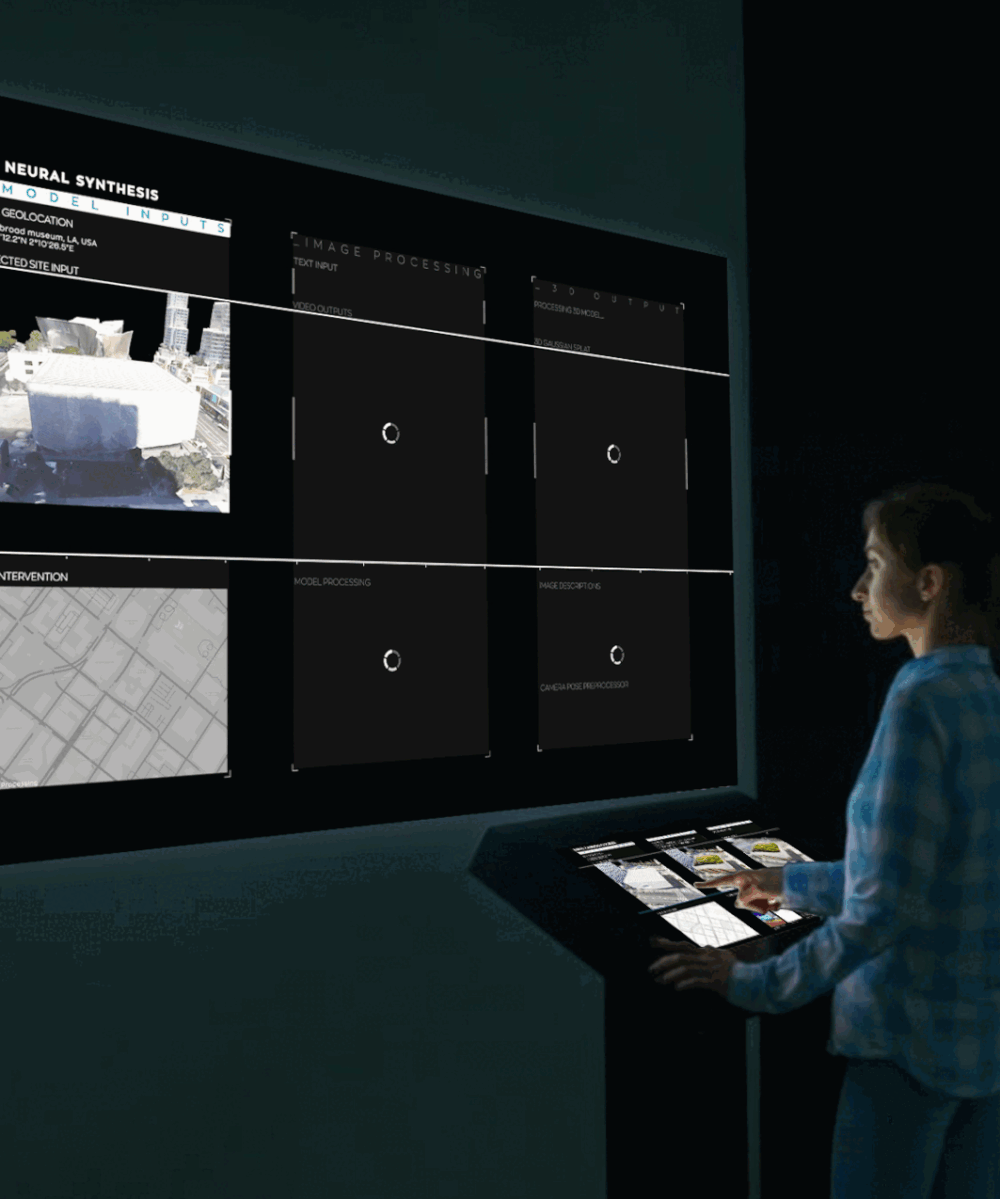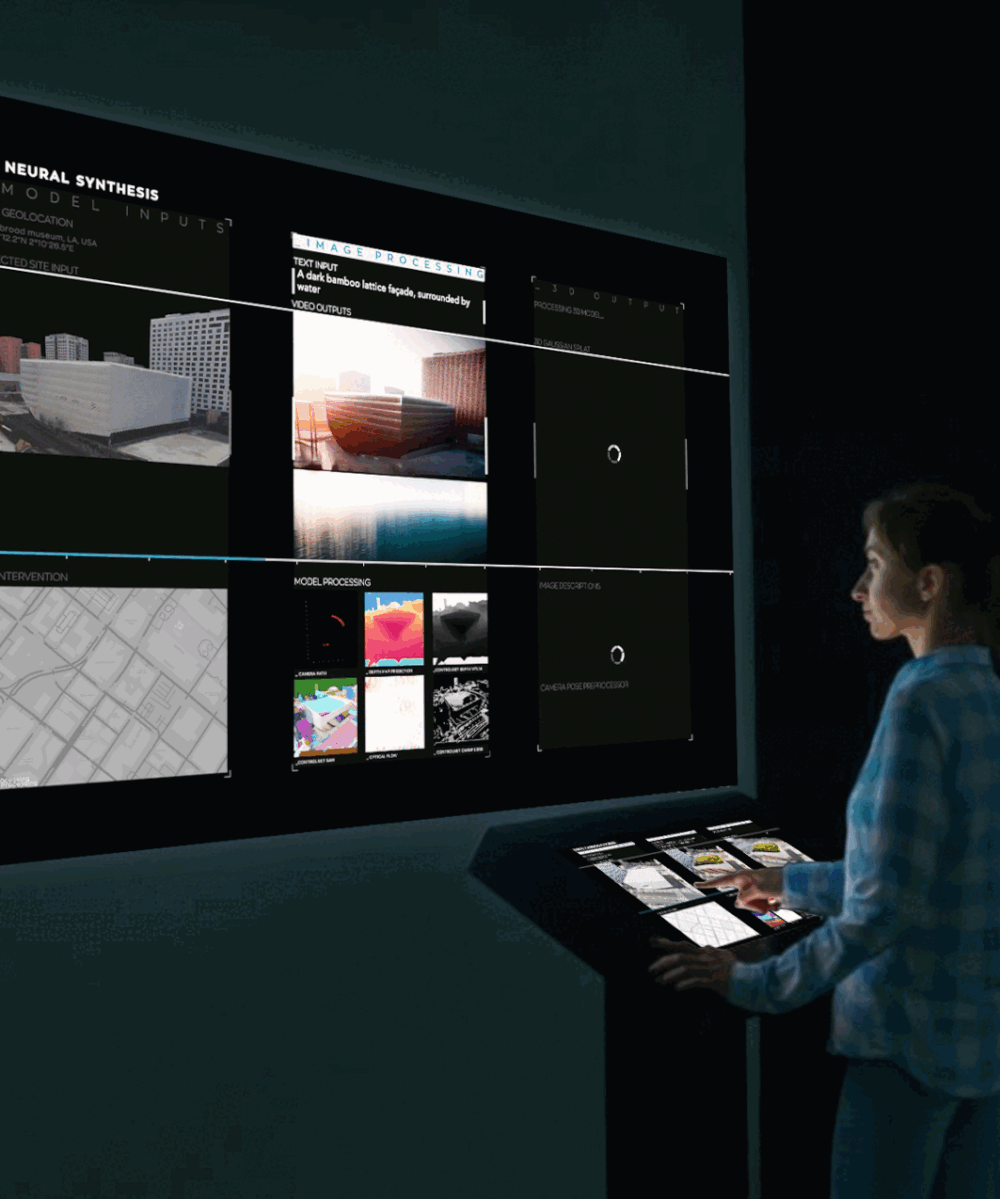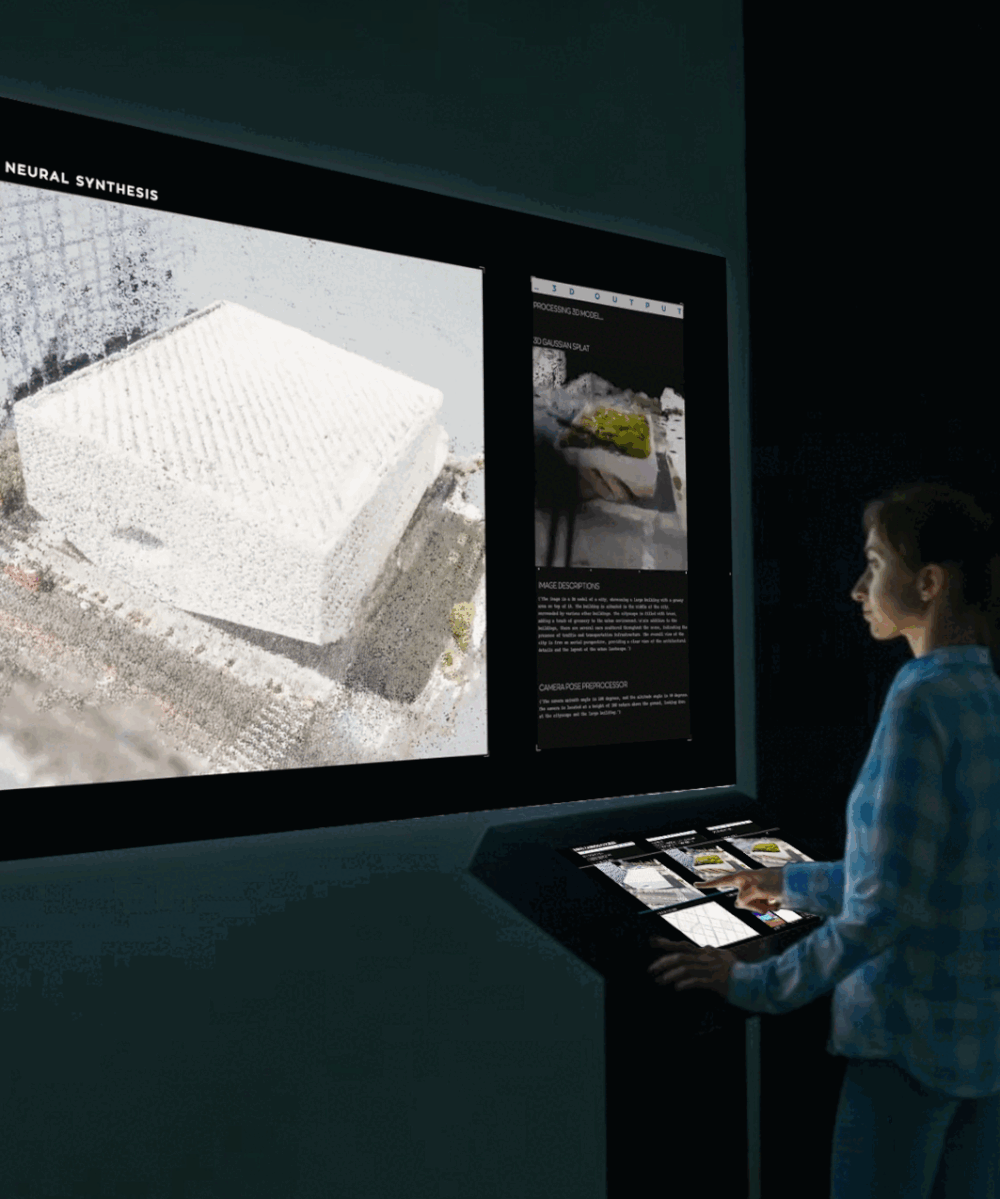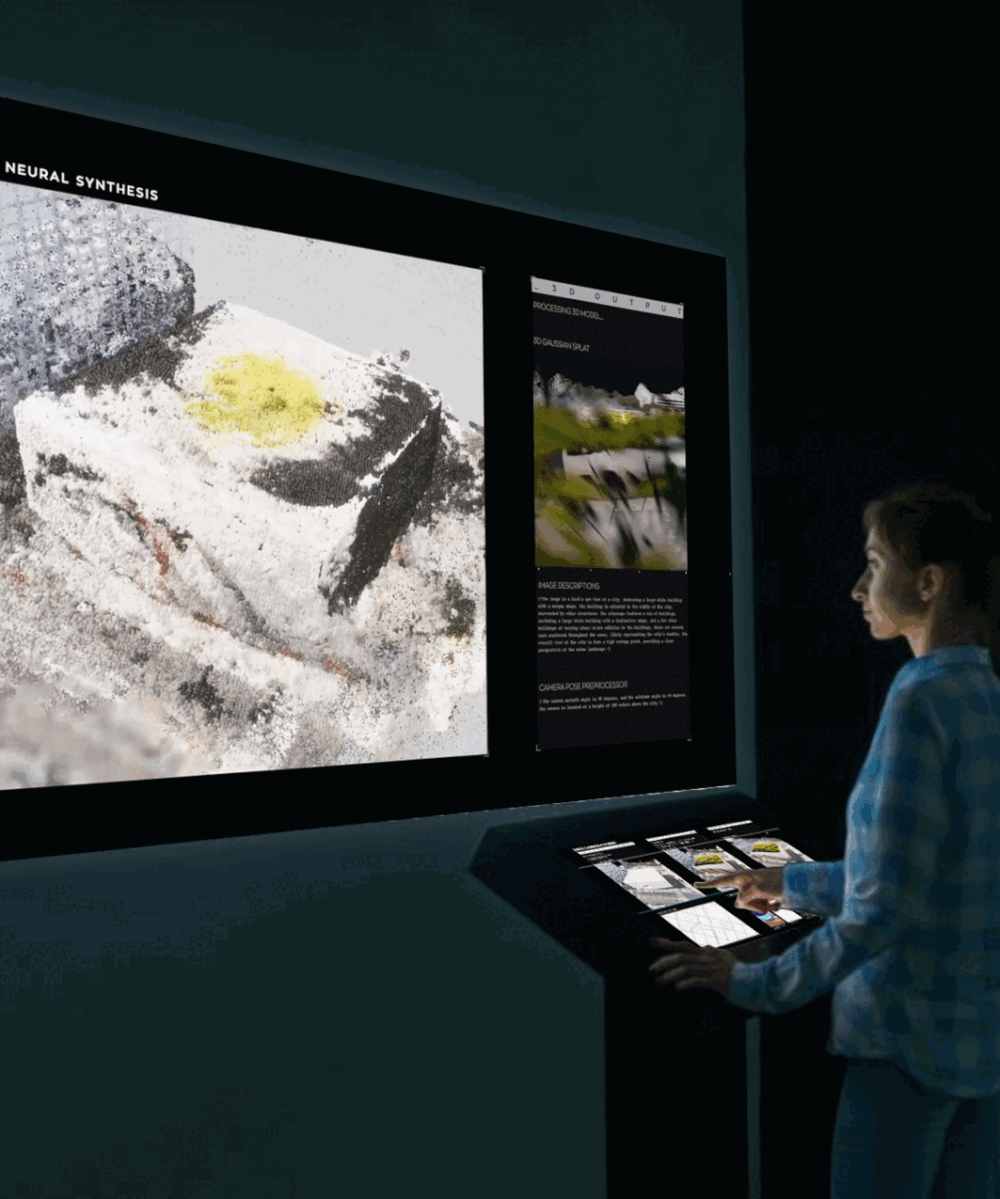
Algorithmic Opacity and Transparency: it is possible or desirable to shed light on Black Boxes?
by Fabio Gnassi
Unlike the great inventions of the past, which were tangible and visible, algorithms operate opaquely, hidden behind complex mathematical language. In a historical moment where these digital entities not only observe but influence our daily lives, the need to shed light on these mechanisms has become essential.
Claudio Agosti (vecna) is a self-taught hacker from the past century, fascinated by the challenge of how humanity can use the internet as a tool for liberation and disintermediation. For him, cryptography, peer-to-peer networks, bypassing censorship, and critiquing digital power are daily bread. He is a member of Hermes – Hacking for Human Rights.
Agosti founded Tracking Exposed, a project born in 2016 as a pioneer in algorithm analysis. He later diversified his activities in 2023 by launching three new projects: Makhno, AI Forensics (which he co-founded), and Reversing.Work. The latter focuses on reverse engineering—a process of analysis that allows for reconstructing the internal workings of a system—and played a key role in initiating an investigation against Foodinho, the food delivery company through which Glovo operates in Italy. This investigation concluded with the Italian Data Protection Authority imposing a five-million euros fine on the company.

Your interest in algorithms and their functioning lies at the core of Reversing.Work and AI Forensics. Could you describe these two projects, highlighting the motivations behind their inception and the goals they aim to achieve?
It has been twenty years since I wrote my first article criticizing Google’s search engine, in which I identified the power of the American company to shape public perception through studying and manipulating users’ knowledge profiles. Back then, proving this was difficult; it seemed like a conspiracy theory. But the time to understand the power algorithms have in influencing society was already ripe. Consider, for instance, the study published ten years ago that demonstrated Facebook’s ability to manipulate its users’ emotions by controlling what they see. Unfortunately, it took abuses and whistleblowers for this problem to start becoming clear even outside my bubble.
In light of this, the primary goal of my work is to raise awareness. People need to understand that they are not in control of their own time and digital experience. They think they are, but they are not. The secondary goal, then, is to give citizens the power of choice that algorithms currently hold. The algorithm acts as a filter that selects information to decide what should be seen, and our aim is to shift control of this filter from companies to individuals.
the primary goal of my work is to raise awareness. The secondary goal is to give citizens the power of choice that algorithms currently hold.
Your research activities aim to use algorithms as tools to explain the new power dynamics characterizing the contemporary era. Could you provide some significant examples of your work?
To answer this question, I’ll refer to two relatively recent events.
The first dates back to March 2022, when Russian TikTokers began expressing dissent against the invasion of Ukraine. In response, the Kremlin passed a law banning the use of the word “war,” mandating the term “special military operation” instead. The Silicon Valley platforms opposed this request, while TikTok acted differently, following an operational mode we already know. TikTok’s content moderation is not globally standardized but tailored to each country, and the moderation (or blocking or censorship) of specific content can occur in more or less subtle ways. For example, when you search for something prohibited in Italy, the system displays a message explaining that “what you are looking for is prohibited by our guidelines” or “no results were found.” One of TikTok’s censorship options also includes polluting the results by displaying a series of unrelated videos.
This research was conducted with the University of Amsterdam. The accompanying image summarizes the results:
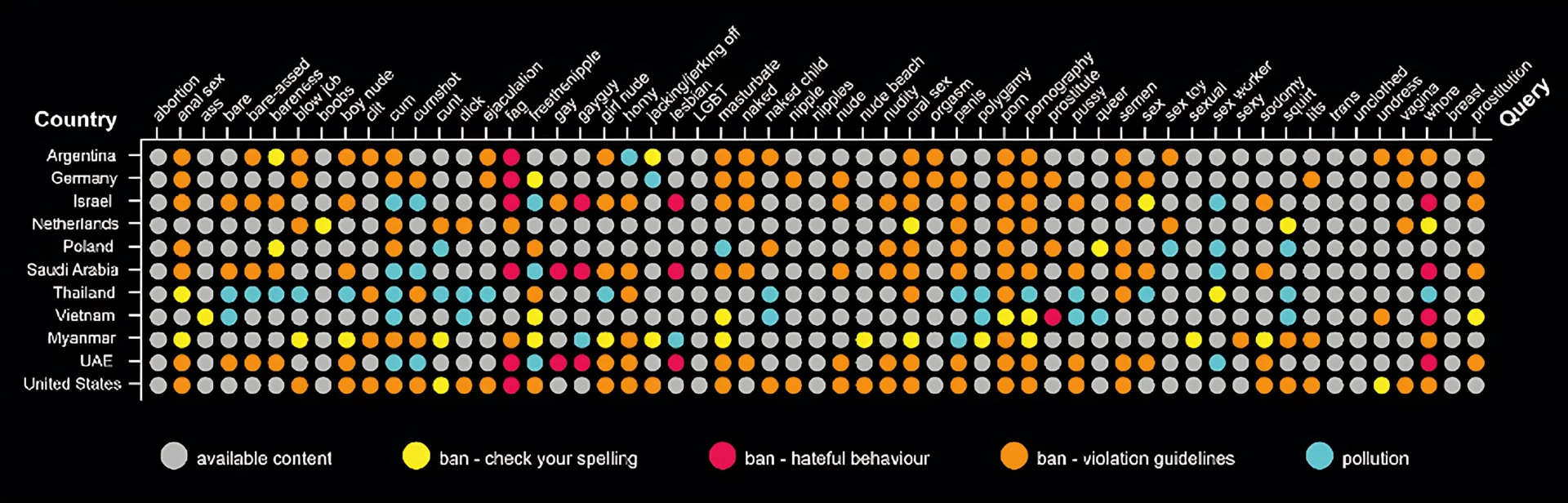
Vertically, you see the “exit points,” or the countries where the searches were performed. Thanks to VPN use, we tricked TikTok’s algorithm into believing we were in different parts of the world. This way, we studied the results of keyword searches (related to sexual themes) listed on the horizontal axis. The study aimed to verify whether certain keywords were blocked in specific nations. The findings allowed us to observe three different types of bans and various pollution attempts, represented by different colors on the chart.
Returning to the Ukraine invasion: while it’s easy for TikTok to block certain keywords and demonstrate compliance with state demands, users can often find ways around the blocks. For instance, if an influencer posted a video dancing with a sign saying “Stop the War,” without hashtags or using the word “war” in the description, it would be challenging for TikTok to remove it automatically. Intervention would only occur after the video garnered thousands of views, making censorship attempts obvious and triggering the so-called “Streisand Effect” (look it up on Wikipedia!). TikTok’s response to this situation was unprecedented. They geographically fragmented their network, preventing Russian citizens from uploading videos and rendering all non-Russian profiles invisible.
Although this choice might seem like economic suicide, this mechanism allowed influence operations to disseminate propaganda content while disadvantaging internal political opponents, who were denied the same opportunity. According to Motherboard, some influencers sponsored by the Kremlin could still upload videos using an atypical workaround. By leveraging mobile devices, they could save the video as a draft and publish it using a computer geolocated outside Russia via VPN.
The following graph describes the impact of this action on videos discussing the invasion.
This example shows how explaining the power algorithms exert over civil society is neither easy nor quick. There’s a lot of context to share, which must then be combined with platform policies. Long-term effects, which can only be estimated through aggregated data analysis, would require individual surveys to verify. There are also countless invisible and rapid changes in how these technologies function, which might affect only a small population segment. For these reasons, producing investigations that link individual experiences to collective ones is still complex.
The opacity characterizing AI model functioning has led to the emergence of a research field called “Explainable AI” (X-AI), dedicated to developing transparent and comprehensible algorithmic models. What is the state of this field, and how do you evaluate the efficiency of these tools?
It’s like trying to stem a high tide with bare hands and sandcastles. Deep learning originates from a culture where data is owned by the strongest, and no explanations need to be given. The idea that algorithms are so complex even their developers can’t explain them has been propagated for over a decade—a narrative that benefits companies seeing secrecy as a convenient excuse not to explain their power or its ramifications. Deep learning and related research, including large language models, deliver revolutionary results but at the expense of values once fundamental to computing. Reproducibility, for instance. The certainty of obtaining the same result given the same input is no longer guaranteed. Similarly, it’s impossible for two people to create the same language model.
We’ve shifted from a discipline where every bit was in its place and the outcome could be retraced to one that relies on chance. While the amazing advancements of recent years make criticism seem futile, this shift represents a radical departure from how computer science was conceived and offers fewer guarantees.
Take genetically modified organisms (GMOs) as an analogy. In the past, seeds were subjected to random mutations via radioactive agents, and only afterward could useful mutations be identified. Now, with CRISPR and other genome-editing systems, we know where we intervene (even if outcomes remain unpredictable, there’s some control). Artificial intelligence is undergoing a similar historical transition.
The theoretical issue is that 20 years of computing production have conditioned users/consumers not to ask questions. Accept what happens, and if necessary, turn it off and back on. Computing was initially a discipline that helped rethink problems, decompose them, and solve some parts using machines. The difference in cultural assumptions and original objectives is still difficult for me to accept. The AI-based products you see today, relying on interaction between users and AI, are just a phase. The goal of current developments is to make AI invisible, integrate it into operations, and potentially strip further decision-making ability from people.
Explainable AI (XAI) is a field attempting to make algorithm functionality understandable to developers. This year, I collaborated with unions and other institutions to explore how to adopt AI in the workplace. One of the proposed—but hard to implement—solutions was adopting XAI systems. These systems were considered for gig workers, like delivery drivers or Uber drivers. However, from my perspective, this is not the solution. For end workers, understanding “how the algorithm works” might not matter. What’s important is the ability to organize their time and resources, which the application must facilitate.
The main issue is how AI applications are used. When no means are provided to learn, understand, or control the tool, but only to use it, workers become mere executors of pre-decided tasks. This problem is more political than technological. It also surfaces when Google decides for you, or when Facebook promises to show only relevant content. Whether it’s a language model or an anti-spam system, the key question remains: “Where does the power lie?”